






Illustratorのアウトライン解除はできないが、できるだけ復元する方法
デザイナーMM
2019/05/19
はじめに
こんな人に向けた記事です。
- illustratorデータを誤ってアウトライン化してしまった
- アウトライン後のデータしかもらえないけど修正しないといけない
どっちも、ときどきありますよね。
アウトライン化されたデータの完全復元方法はありません!
アウトライン化されたものを復元する機能はありません。ただし、できるだけ復元する苦肉の策はあります。
イラレのアウトラインのテキスト情報を抜き出す方法
この方法は、そのまま復元できるわけではなく、テキスト情報だけ抜き出して、イラレストレーターで組み直しになります。
イラレの背景などの装飾のカット
aiファイルを一つ複製します。そして、そのファイルの背景などできるだけ取り除きましょう。文字がなるべく読み取りやすいように、文字に被る装飾を削除します。

PDF互換ファイルを作成をチェックして保存
装飾の削除が終わりましたら、PDF互換ファイルを作成をチェックして、一旦保存します。
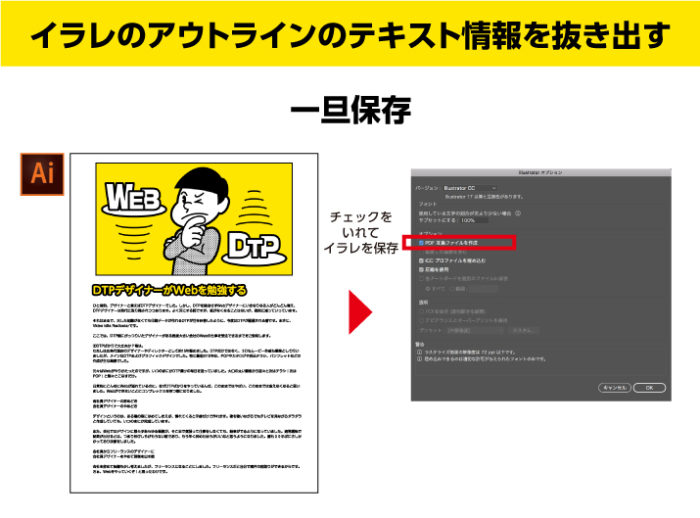
aiデータをAdobe Acrobatで開く
aiデータをイラレで開くのではなく、アクロバットで開いてください。アクロバットReaderではなく、アクロバットで開きます。
そのあと、「ツール」→「PDFを編集」をクリックします。

アウトラインデータのテキストが抜き出せます
これでテキストが、抜き出せます。もちろん、画像のテキストは抜き出せません。また加工した文字は抜き出せません。

全てのテキストを抜き出せるわけではない
この例のテキストの場合「ー」の部分が分割されています。
たくさんの文字が分割されて、コピーするより新しく文字を打ったほうが早いレベルのエラーや、一文字抜けたりするようなエラーもよく起こります。

似ているが、ちょっと違う漢字に置き換わることがあります。「力」と「刀」や「眠」と「眼」などです。仕方がないなと思う反面、似て非なるものが入ったテキストは、新たな問題が発生します。
あっている眼で校正すると、その微妙な違いに気がつかないのです。これが大きな問題になることがあります。
ミスなくテキストを修正する方法
PDFから文字変換でできたaiデータの一番の問題点が、似て非なるパッと見ではわからないデータができてしまうこと。それを回避するために、作り直したaiデータを正しいPDFの上に重ねます。その際、正しいPDFの透明度をさげて重ね合わせます。
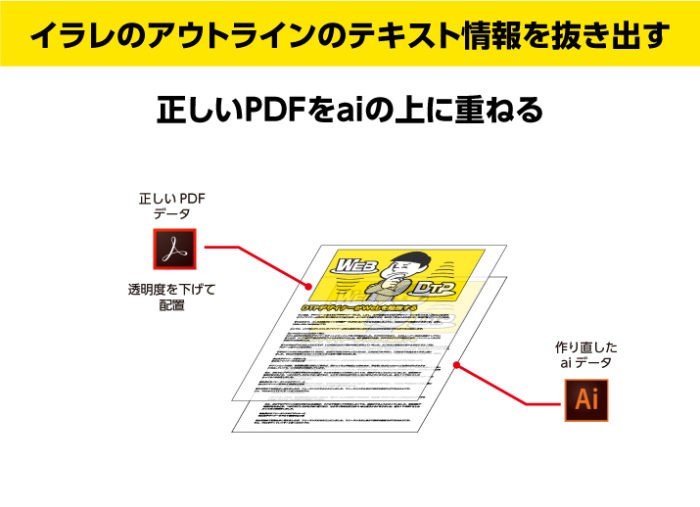
重ねることで、微妙な変化がわかりやすく浮かび上がってくるので、とてもオススメのチェック方法です。




デザイナーMM
ハードコアな音楽とホラー映画を愛するデザイナー。PUBGの実況動画をご飯を食べながら見るのが趣味
コメント2件
-
 take より:
take より: はじめまして、アウトラインの支給データを修正する仕事が多いデザイナーです。
Ai→PNG書き出し→GoogleドライブにUP→Googleドキュメントで開く
でも同様にテキスト化できるのでオススメですよ。
「ー」とかが半角になるなどの精度は同じくらいですが、
Googleは修飾・加工してあるテキストも読み取ってくれることが多いです。-

なんと!!!この方法を試して、後日追記させていただきます!!ありがとうございます。
-






コメントを投稿する